The Bayesian Brain
The Bayesian Brain
The hypothesis that the brain is fundamentally an inference engine. Perception, cognition, and action are not passive processes but active Bayesian computations: the brain continuously generates predictions about the causes of sensory input, then updates those predictions based on incoming evidence. What we experience as reality is a posterior belief, not a direct readout of the world.
This framework unifies an extraordinary range of phenomena under a single computational principle: minimize surprise (or equivalently, minimize free energy). Attention, learning, action, psychedelic states, meditation, and selfhood all find natural explanations within it.
Source: Shamil Chandaria, “The Bayesian Brain and Meditation” (Waking Up / Sam Harris).
The perception problem
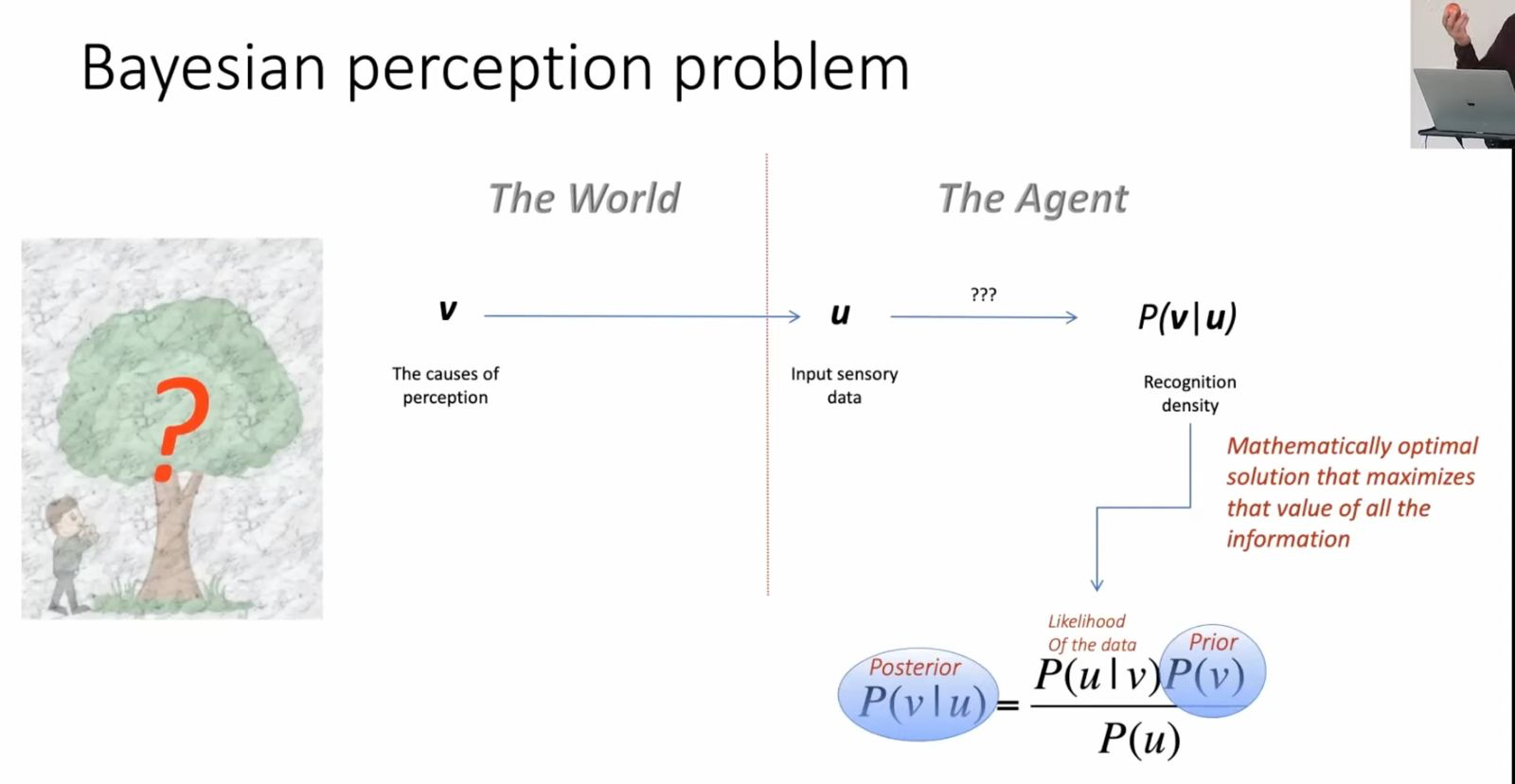
The world contains hidden causes v (objects, events, states) that generate sensory data u through causal processes. The agent never has direct access to v, only to u. The fundamental task of perception: infer the hidden causes from the sensory evidence.
Bayes’ theorem gives the mathematically optimal solution:
P(v|u) = P(u|v) P(v) / P(u)
| Term | Name | Meaning |
|---|---|---|
| P(v|u) | Posterior | What to believe about the world given the data |
| P(u|v) | Likelihood | How probable this data is given a particular world state |
| P(v) | Prior | What was believed before the data arrived |
| P(u) | Evidence | Marginal likelihood, a normalizing constant |
This is the recognition density: the brain’s best guess about reality. It is the mathematically optimal solution that maximizes the value of all available information.
The catch: exact Bayesian inference is computationally intractable for anything beyond toy problems. Real brains, with real-time constraints, need an approximation.
The variational algorithm
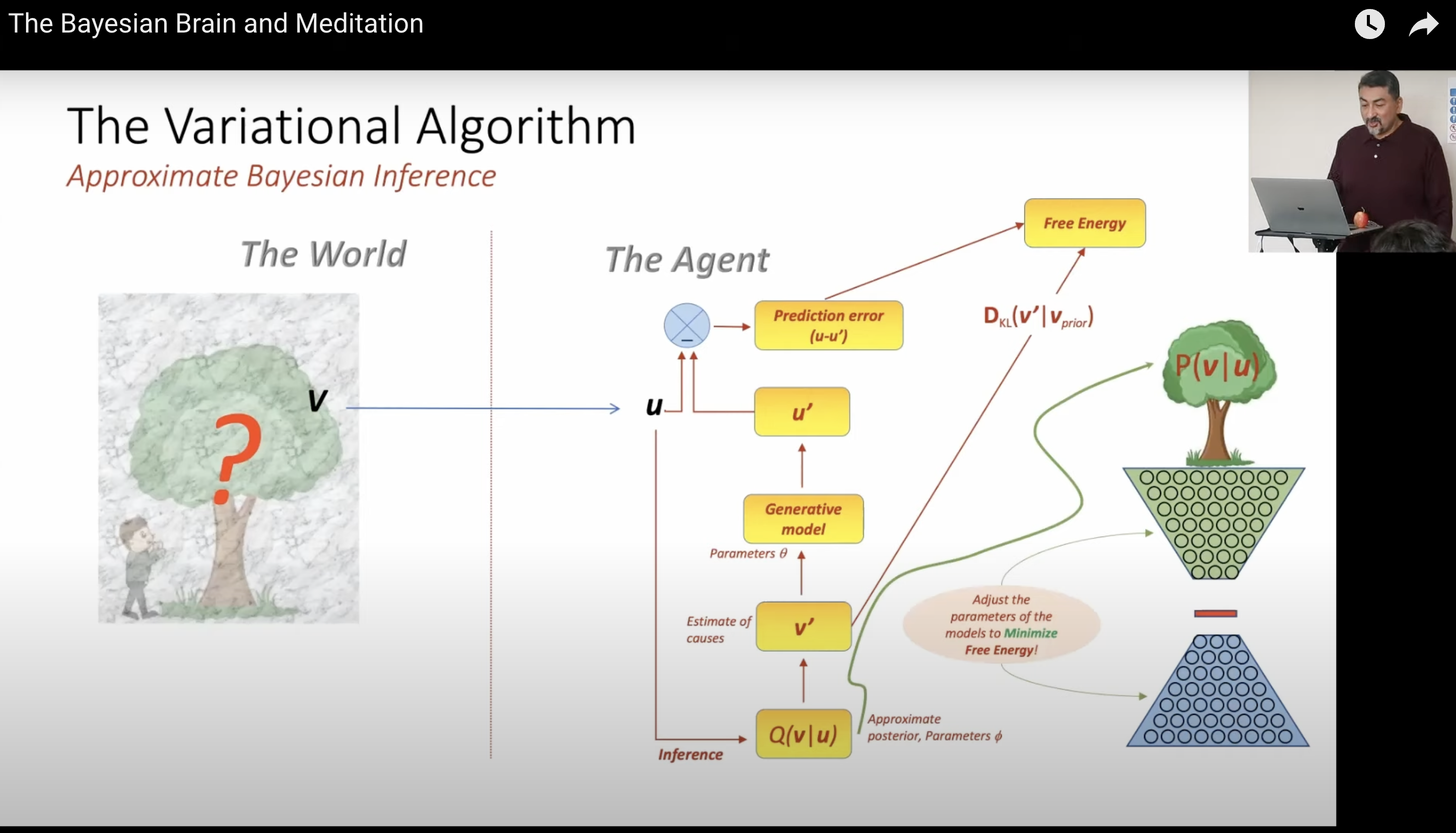
The brain’s proposed solution: variational inference. Instead of computing the true posterior P(v|u) directly, the brain maintains:
- A generative model: an internal model of how hidden causes produce sensory data
- An approximate posterior Q(v|u): the brain’s current best guess, parameterized for tractability
- Free energy F: a computable upper bound on surprise (-log P(u))
The algorithm loop:
- Sensory data u arrives from the world
- The generative model produces predictions u’
- Prediction error e = u - u’ is computed
- Model parameters are adjusted to minimize free energy
Free energy decomposes into two terms:
- Reconstruction accuracy: how well the model explains the data
- KL divergence D_KL(Q || P_prior): how far the approximate posterior has drifted from prior beliefs
Minimizing free energy simultaneously makes the model better at explaining data AND keeps beliefs close to priors. This is a built-in Occam’s razor: the simplest explanation consistent with the evidence wins.
This is the core of Friston’s free energy principle: all adaptive systems minimize a variational free energy bound on surprise. It’s not just a model of the brain. It’s proposed as a universal principle of self-organizing systems.
Precision weighting and attention
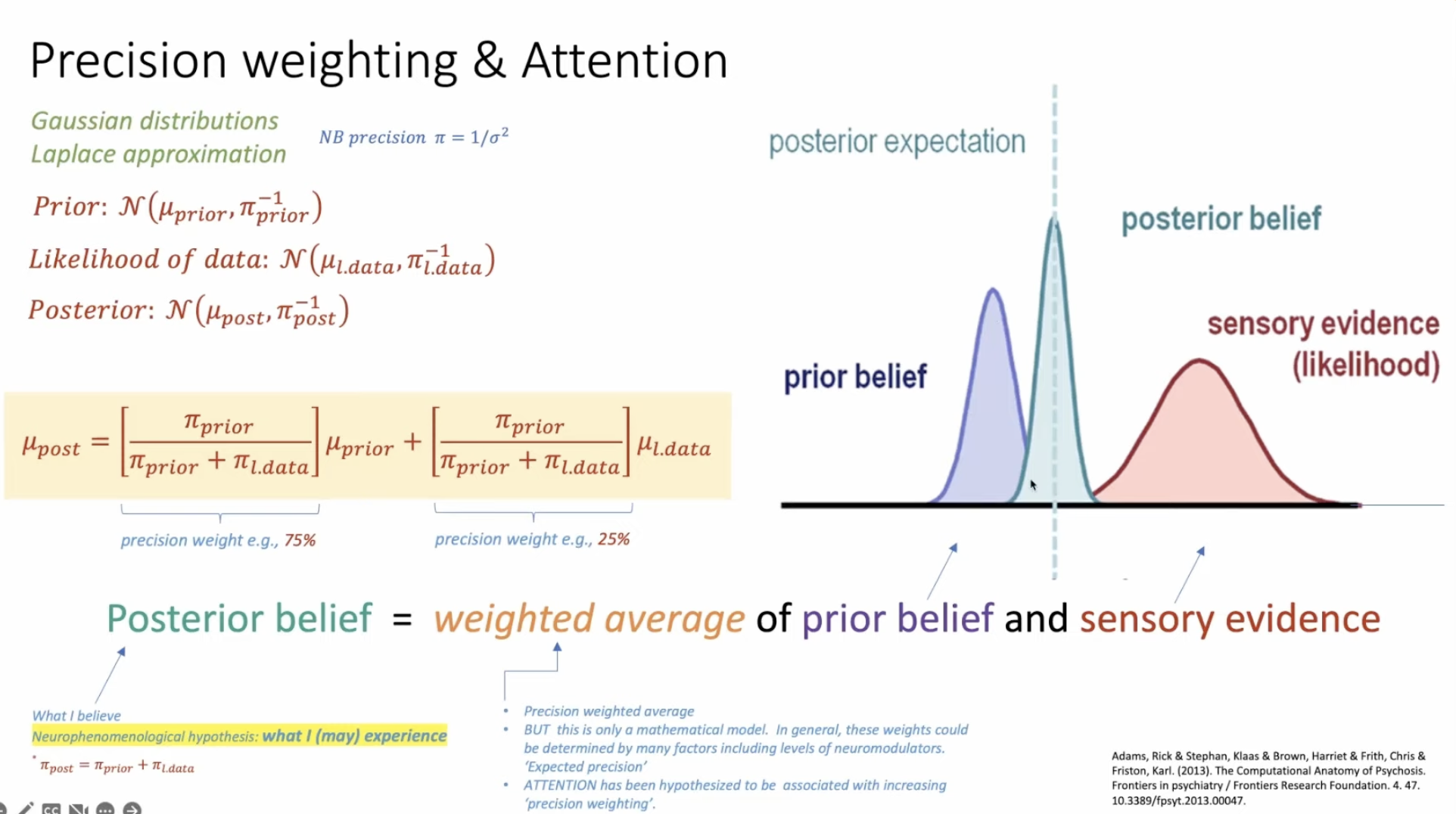
Under Gaussian assumptions (Laplace approximation), Bayesian updating becomes elegant. Prior, likelihood, and posterior are all Gaussian distributions, and the posterior mean is simply:
μ_post = w_prior · μ_prior + w_data · μ_data
where the weights are precision ratios:
| Weight | Formula | Meaning |
|---|---|---|
| w_prior | π_prior / (π_prior + π_data) | How much the prior belief counts |
| w_data | π_data / (π_prior + π_data) | How much the sensory evidence counts |
Precision π = 1/σ² (inverse variance). High precision = tight distribution = high confidence. Low precision = wide distribution = uncertainty.
The posterior is literally a precision-weighted average of what you believed and what you observed. Tight, confident priors dominate noisy data. Sharp, reliable evidence overrides vague priors.
The punchline: attention is precision weighting. When you attend to something, you increase the expected precision of prediction errors in that sensory channel. This makes the evidence count more against prior expectations. Attention doesn’t change what you see. It changes how much what you see matters relative to what you expected.
Note: this is a mathematical idealization. In practice, precision weights are modulated by neuromodulatory systems (dopamine, norepinephrine, acetylcholine, serotonin), not just by abstract optimality.
The global predictive hierarchy
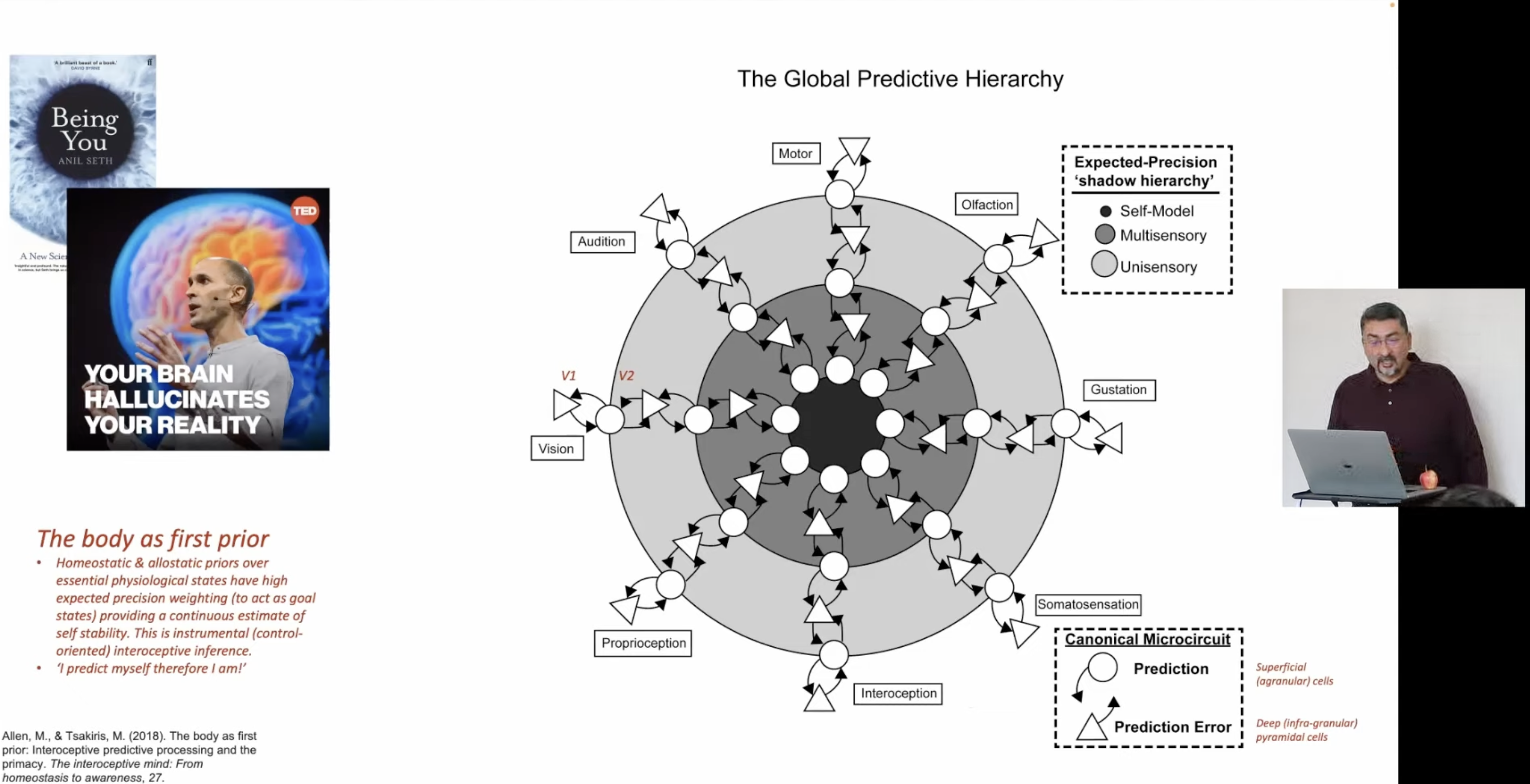
This isn’t a single layer of prediction. The brain implements a hierarchical generative model spanning every sensory and motor modality: vision, audition, olfaction, gustation, proprioception, interoception, somatosensation.
At each level of the hierarchy:
- Predictions flow downward (from deeper, more abstract layers)
- Prediction errors flow upward (from superficial, sensory-facing layers)
The canonical microcircuit implements this division of labor: deep cortical layers generate predictions (large receptive fields, slow dynamics), superficial layers compute prediction errors (small receptive fields, fast dynamics).
Running alongside this is an expected-precision “shadow hierarchy” that tracks confidence at each level:
- Unisensory (raw sensory channels)
- Multisensory (cross-modal integration)
- Self-model (the highest level)
The body as first prior (Allen & Tsakiris, 2019). Homeostatic and allostatic priors over essential physiological states carry the highest expected precision weighting. Before the brain predicts anything about the external world, it predicts its own continued viability. The organism’s most fundamental inference is interoceptive: am I alive? Am I stable?
“I predict myself therefore I am”: selfhood as interoceptive inference. This connects to Anil Seth’s “controlled hallucination” framework (Being You, 2021): consciousness is not perception of reality but the brain’s best prediction of reality, constrained from below by sensory evidence and from above by the self-model.
Experience as constrained construction
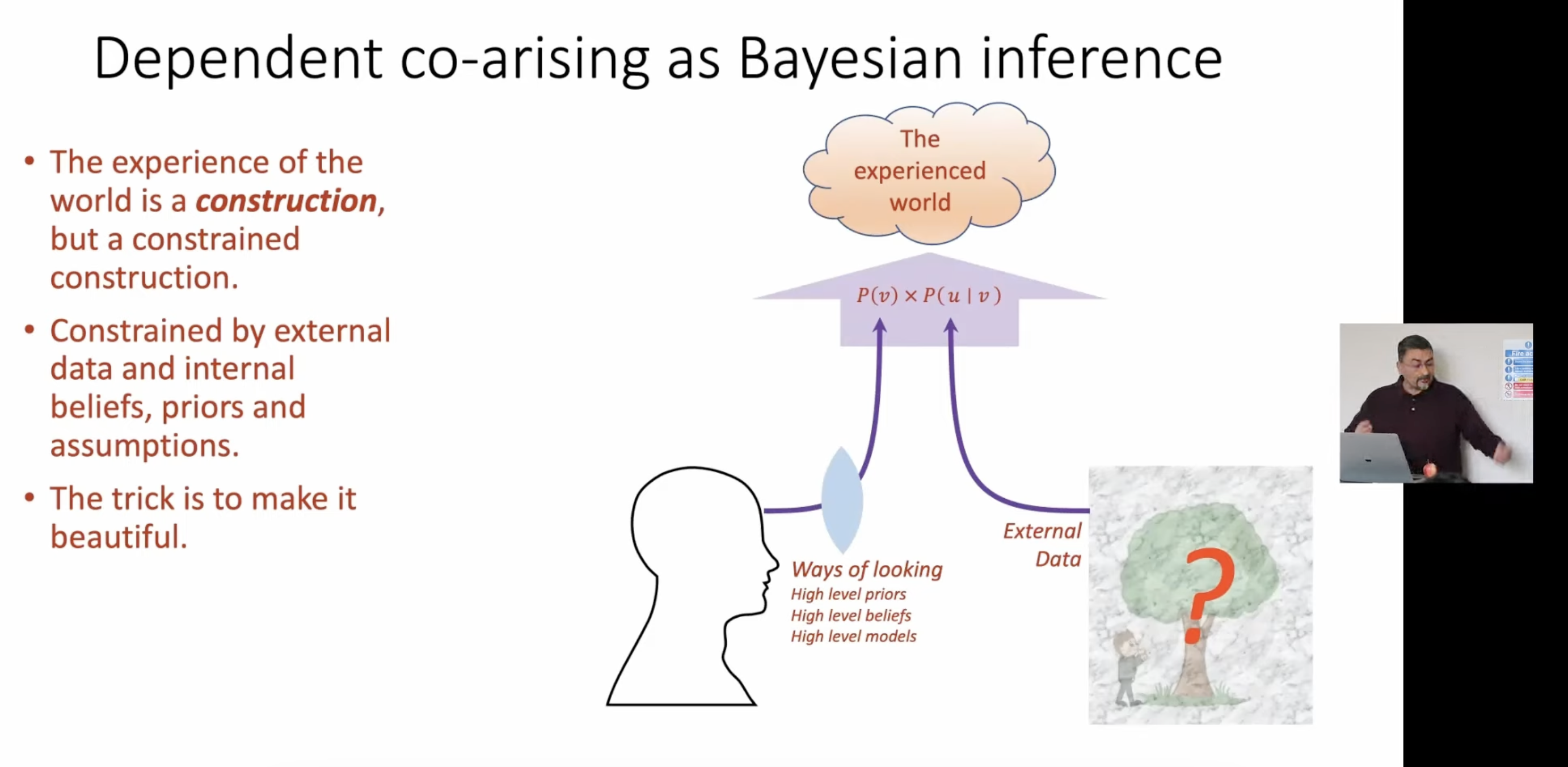
Chandaria draws a striking parallel: the Bayesian brain maps onto the Buddhist concept of dependent co-arising (pratītyasamutpāda). The experienced world is a construction, but a constrained one. It arises in dependence on:
- External data: the sensory signal, the world pushing back
- Ways of looking: high-level priors, beliefs, models, attentional stances
Neither alone produces experience. The world without a model is unstructured noise. A model without the world is unconstrained hallucination. Experience lives in the intersection: P(v) × P(u|v). The experienced world is what emerges when prior beliefs meet sensory constraint.
“The trick is to make it beautiful.”
This is not a throwaway line. If experience is a construction (if the priors you bring shape the world you inhabit), then the quality of your priors is an ethical and aesthetic question. Contemplative practice (meditation, psychonautics) can be understood as the systematic refinement of the “ways of looking” that co-construct experience.
Belief attractors and psychedelics
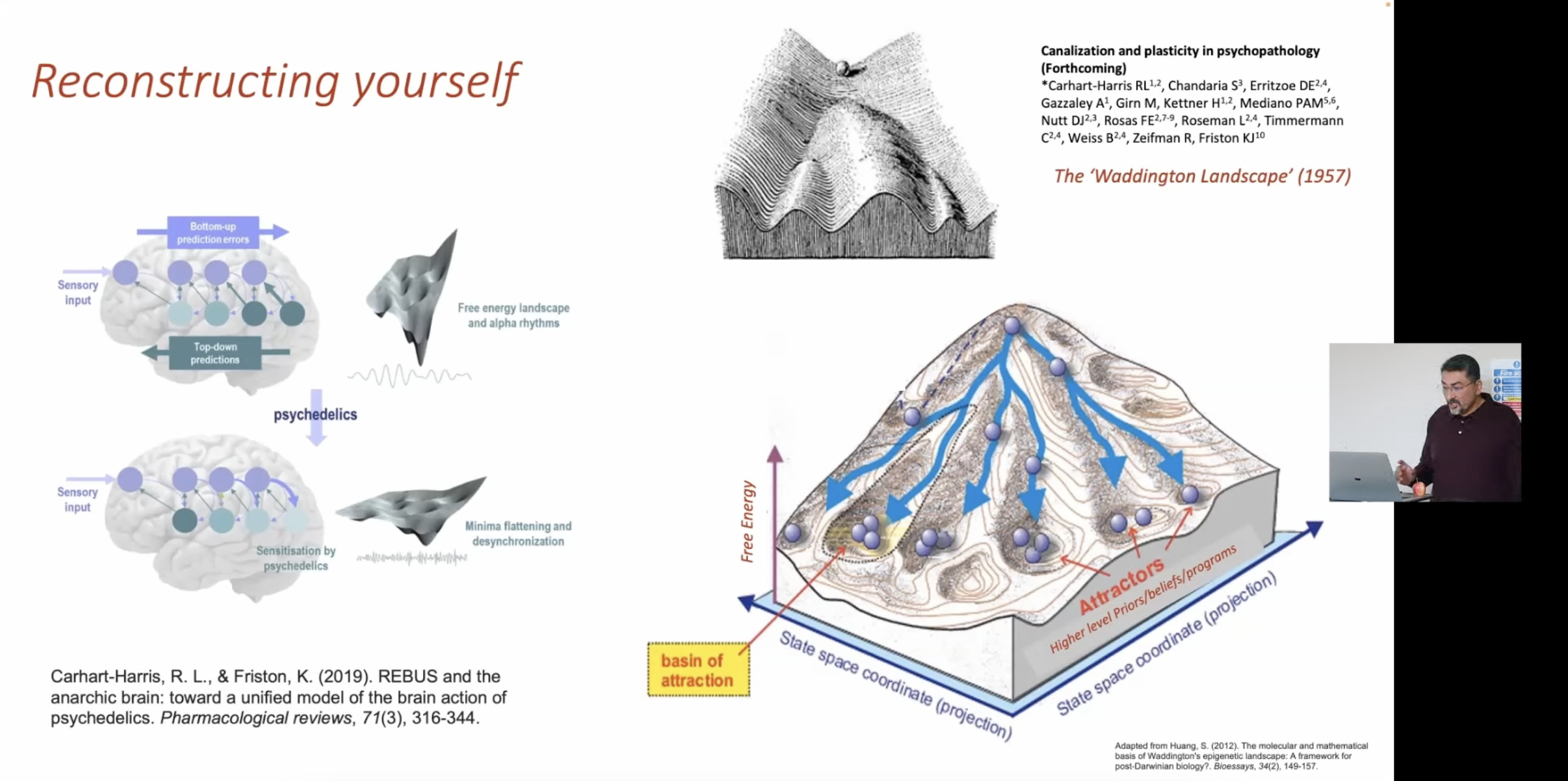
The free energy landscape defines basins of attraction: stable configurations of belief that the system settles into. The Waddington landscape (1957) provides the visual metaphor: a marble rolling down channels that deepen and narrow over time. Development, learning, and habit all carve grooves into the landscape. Deep grooves = high-precision priors = rigid patterns of inference.
The REBUS model (Relaxed Beliefs Under Psychedelics; Carhart-Harris & Friston, 2019) proposes that psychedelics work by flattening the free energy landscape. They reduce the precision weighting of high-level priors, loosening the top-down grip on perception and cognition. The system escapes deep attractors and can explore new regions of state-space.
This is why psychedelic experience simultaneously feels like dissolution (old patterns breaking apart) and revelation (new patterns becoming accessible). The landscape hasn’t changed. The marble is just free to roll.
Clinical implications: depression, addiction, and OCD can be modeled as pathologically deep attractors: beliefs and behavioral patterns with too much precision, too resistant to updating by new evidence. Psychedelics (and potentially meditation) offer a mechanism for reconstructing yourself by temporarily flattening the landscape and allowing recanalization into healthier basins.
The slide references forthcoming work on “Canalisation and plasticity in psychopathology” with Carhart-Harris, Chandaria, and others, suggesting this is an active research program, not just a metaphor.
Evolutionary roots: why Bayesian inference at all?
The predictive processing framework is typically introduced through neuroscience — the architecture of cortical hierarchies, mismatch negativity, precision-weighted updating. But the deeper question is: why should any adaptive system do Bayesian inference in the first place?
Intelligence as Self-Modeling provides the first-principles answer. Any agent that must survive in a variable environment implicitly learns a joint distribution P(X,H,O) over external observations (X), internal state (H), and its own actions (O). This is what a bacterium does when it estimates chemical concentration via a running average of molecular docking events: it is compressing a high-dimensional sensory stream into the latent variable (concentration) that is predictively relevant for its survival. No brain required.
The Bayesian brain is this same computation at higher resolution. Precision weighting is the mechanism for arbitrating between prior belief and incoming evidence — the same tradeoff a bacterium makes when it adapts its time window for concentration averaging. The hierarchical generative model is a deep latent variable structure over a much richer X and H. Active inference (acting to fulfill predictions) corresponds to the bacterium’s run-tumble decisions conditioned on estimated concentration and hunger.
What this grounding adds: Bayesian inference is not a clever trick brains invented. It is the necessary computational architecture of any adaptive agent under selection. The bacterium derivation shows that evolution, as the outer loop of unsupervised learning, will converge on approximately Bayesian behavior wherever it operates. Predictive processing in the cortex is not “the brain approximating Bayes” — it is the latest and most elaborate instance of a computation that has been running for ~4 billion years.
Related pages
- Cephalization from Below: the evolutionary prequel: how nerve nets, brains, and neuromodulatory systems arose to serve muscular coordination, producing the predictive machinery that this page describes
- Intelligence as Self-Modeling: the first-principles evolutionary derivation showing Bayesian inference is the necessary architecture of any adaptive agent; the bacterium as Bayesian agent grounds P-001 independently of neuroscience
- Computational Being (Bach): Bach’s “self-organizing game engine with inverse rendering” is this same framework in different language; his model of the self (agent + demands + control model) maps onto the generative model + precision weighting architecture
- Controlled Hallucination: the phenomenological counterpart to this page; Seth maps the predictive processing machinery onto conscious experience, selfhood, and the “real problem” strategy
- Complexity Measures of Consciousness: how the computational machinery described here gets measured empirically (PCI, LZW), plus Ruffini’s KT as the information-theoretic formalization
- P-001: Perception is inference: the foundational prior underlying this entire framework
- P-002: Experience is a constrained construction: the dependent co-arising insight, bridging computation and contemplative practice
References
- Carhart-Harris, R. L., & Friston, K. (2019). REBUS and the anarchic brain: toward a unified model of the brain action of psychedelics. Pharmacological Reviews, 71(3), 316-344.
- Adams, R., Stephan, K., Brown, H., Frith, C., & Friston, K. (2013). The Computational Anatomy of Psychosis. Frontiers in Psychiatry.
- Allen, M., & Tsakiris, M. (2019). The body as first prior. The Interoceptive Mind.
- Seth, A. (2021). Being You: A New Science of Consciousness. Faber & Faber.
- Chandaria, S. “The Bayesian Brain and Meditation.” Waking Up (Sam Harris).